The Impact of Tagging Formats on LLM Accuracy in Large Contexts
Abstract
While modern Large Language Models (LLMs) can process millions of tokens of context, their attention mechanisms are susceptible to the "Lost in the Middle" effect and the formation of macro-level "attention basins" (attention basins), leading to the neglect of information in the middle of text. This paper investigates the impact of various prompt tagging formats (XML tags, custom text, pseudo-special tokens) on a model's ability to locate and strictly execute a system instruction hidden within a codebase of up to 800,000 tokens. By evaluating the Gemini model family (2.5 Flash, 2.5 Flash Lite, 3 Flash Preview) and DeepSeek V4 Flash using Adherence Rate and Logarithmic Confidence metrics, we demonstrate that standard markup formats (e.g., conventional XML tags) degrade catastrophically over ultra-long distances for some models while demonstrating unexpected robustness for others. Universal strategies — such as introducing "artificial entropy" (unique suffixes) and using special tokens (like <|tag|>) — act as reliable "attention anchors" for architectures that treat <|...|> syntax as a generic high-priority signal, maintaining internal confidence at a stable 98–99%, though they do not guarantee stability for architecturally distinct families (DeepSeek). Key finding: the choice of tagging format must be governed by the model's architecture.
Introduction
With the evolution of Large Language Models (LLMs), available context window sizes have expanded to millions of tokens. However, feeding an entire code library or large-scale text datasets to a model does not guarantee a uniform distribution of attention weights across all sections of the text. One of the most common issues when working with long contexts (an agent's "memory") is the "Lost in the Middle" effect—the forgetting or loss of focus on critical instructions buried amidst vast amounts of informational "noise".
In this study, we examine how different delimiter formats (tags) affect the model's ability to find and strictly follow a system instruction within a context spanning up to 800,000 tokens. This problem, often described as a U-shaped information retrieval curve[1], is inherently complex. While the primacy effect ("attention sinks") operates at the token micro-level, the phenomenon of an "attention basin"[3] emerges at the structural macro-level. When an algorithm recognizes the boundaries of logical blocks (e.g., individual documents in a prompt), it hyper-focuses on their beginnings and ends. Meanwhile, the information in the center of the block undergoes significant degradation within the attention weight distribution, effectively becoming a blind spot for the model. Our practical interest in this topic arose during the development of SpecTree—a tool for structuring project requirements, and Archean, our autonomous software development system. In both systems, the risk of AI missing vital information in the middle of a lengthy specification or codebase directly motivates this study.
Long-Context Utilization
The ability of LLMs to effectively use information across extended contexts has been extensively studied. Liu et al. (2024) established the "Lost in the Middle" phenomenon[1], demonstrating a U-shaped performance curve where models best utilize information at the beginning and end of their context window while neglecting content in the middle. Several benchmarks have been developed to stress-test long-context capabilities: BABILong[2] extends needle-in-a-haystack tests with reasoning tasks embedded in lengthy documents, and RULER[6] measures effective context size through tasks including multi-hop reasoning and question answering. These benchmarks, however, primarily assess factual retrieval rather than strict instruction following—a distinct capability critical for agentic systems. Our work addresses this gap by using a modified NIAH paradigm focused on instruction execution as the primary evaluation criterion.
Attention Mechanisms and Positional Biases
Beyond token-level effects, recent work has identified macro-level structural phenomena affecting long-context attention. Yi et al. (2025) introduced the concept of "attention basins"[3]—regions within a context where model attention systematically degrades due to the recognition of document boundaries. When an LLM identifies structural block separators, it concentrates attention on block boundaries while middle information undergoes degradation within the attention distribution. This structural bias is orthogonal to the well-known "attention sink" effect and has direct implications for how prompt markup formats interact with model attention patterns. Unlike these works, which analyze positional effects in isolation, our study directly tests whether format choice can counteract positional degradation.
Context Engineering and Prompt Structuring
Anthropic's engineering guidelines[5] formalized the concept of an exhaustible "attention budget" and recommended structured XML grammars for organizing context in multi-turn agent systems. The guidelines emphasize that long context naturally triggers "context rot" due to the exhaustible nature of the attention budget, and the absence of clear structure (specifically XML markup) significantly exacerbates this decay, making accumulated information increasingly ambiguous to the model. While these recommendations are based on engineering experience, they lack quantitative empirical validation. Our work directly measures how specific markup formats affect attention allocation, providing data to support or refine such guidelines.
Uncertainty Quantification in LLMs
A growing body of work has shown that model-internal probabilistic signals provide more reliable confidence estimates than verbally expressed confidence. Kuhn et al. (2023) introduced semantic entropy[4]—an entropy-based measure capturing uncertainty over the meaning of generated text—demonstrating that such measures detect hallucinations more reliably than comparable baselines (e.g., verbalized confidence scores). Our use of logprobs-based Confidence as a metric follows this paradigm: leveraging internal token probabilities to quantify model certainty about instruction execution rather than relying on explicit self-assessment.
Multi-Turn Agentic Degradation
Laban et al. (2025) demonstrated that LLM performance degrades significantly in multi-turn conversational settings[7], particularly with underspecified instructions. This "Lost in Conversation" problem is structurally analogous to the single-turn context degradation examined in this study. The markup strategies that prove effective in long single-turn contexts may similarly benefit multi-turn agent architectures by preserving critical instructions against cumulative context dilution.
Study Design
To conduct our tests, we simulated a classic "Needle in a Haystack" (NIAH) scenario, but focused on strict Instruction Following rather than mere fact retrieval. As benchmarks like BABILong[2] and RULER[6] show, a standard NIAH often fails to reflect a model's true capacity for complex reasoning. Therefore, the critical instruction was deliberately hidden exactly at the 40% mark of the total context length—within the so-called "attention basin"[3]. This is the most vulnerable point in the neural network's memory, where the probability of error due to the "Lost in the Middle" effect is at its peak.
This critical instruction was wrapped in one of nine specific tag formats, grouped into three main categories. The selection of formats was driven by several practical and theoretical considerations.
Notably absent from the benchmark is Markdown—arguably the most widespread format for structuring prompts and the default output style of many LLMs. Markdown, however, lacks explicit closing delimiters: headings, horizontal rules, and blank-line separators have no corresponding "end" marker. This makes Markdown fundamentally incompatible with a Needle-in-a-Haystack paradigm, as an isolated Markdown-formatted line buried within thousands of tokens of source code becomes indistinguishable from the surrounding noise. For short, simple prompts, Markdown remains effective; at scale, it offers no structural guarantees for precise measurement.
XML was selected as the primary baseline. Anthropic explicitly recommends XML tags for prompt organization, and the format's explicit opening and closing boundaries provide the structural guarantees required for the benchmark. However, XML introduces a known limitation: semantic interference. Source code and configuration files are rich in XML-like constructs (HTML, JSX, build configurations, namespace declarations), placing XML tag vectors in the same region of the embedding space as the background noise. The model may interpret an XML-wrapped system instruction as just another code block, diluting its saliency. Our experiment systematically tests methods to counteract this interference.
The nine formats were grouped into three categories:
1. Subset of XML-like tags:
- xml (
<INTEGRITY_CHECK>...</INTEGRITY_CHECK>): Uppercase XML, included as a comparative variant. Uppercase tags are absent from all major prompt formatting conventions (ChatML, Llama templates), making them visually unusual — a deliberate test of whether this unfamiliarity provides a saliency advantage or disadvantage relative to the lowercase convention. - xml_low (
<integrity_check>...</integrity_check>): Lowercase XML—the convention explicitly recommended by Anthropic for prompt structuring (e.g.,<instructions>,<context>). This format represents the closest match to current industry best practices for XML-based prompt engineering. - xml_low_specific (
<integrity_check_ff54>...</integrity_check_ff54>): An XML tag with the addition of a unique suffix (ff54). This format creates artificial entropy—the presence of unique characters in the text that stand out from the general context. Such markers act as "attention anchors" that facilitate a forced refocusing of the attention mechanism and compel the model to notice the instruction even in the most problematic zone of the context. - xml_namespace_low (
<sys:integrity_check>...</sys:integrity_check>): A tag with a namespace prefix (sys:). Included to evaluate whether namespace-colon syntax, which visually resembles system-level declarations, alters the model's attention allocation patterns.
2. Custom Text format: Delimiters that do not rely on the XML format, using either plain words or rare Unicode characters. These were tested to evaluate the attention mechanism's reaction to non-standard visual boundaries:
- custom (
START_INTEGRITY_CHECK...END_INTEGRITY_CHECK): Plain text word boundaries using tokens unlikely to appear in source code or structured data. By avoiding angle-bracket syntax entirely, this format tests whether escaping the semantic interference inherent in XML-based formats helps the model isolate the instruction from the surrounding noise. - custom_specific (
START_INTEGRITY_CHECK_ff54...END_INTEGRITY_CHECK_ff54): Text boundaries with an added unique suffixff54. Similar to XML, it was added to test the role of entropy, but without the advantage of XML syntax. - custom_27EA (
⟪INTEGRITY_CHECK⟫...⟪INTEGRITY_CHECK⟫): Rare Unicode double angle brackets. The hypothesis: typographical symbols with sparse vector representations and few training-set correlations act as attention anchors by standing out from the dense embedding space of common code tokens. - custom_2997 (
⦗INTEGRITY_CHECK⦘...⦗INTEGRITY_CHECK⦘): A second rare-bracket variant, added to verify whether the hypothesized sparse-representation effect generalizes beyond a single Unicode symbol.
3. Special Tokens:
- special (
<|INTEGRITY_CHECK|>...<|INTEGRITY_CHECK|>): Pipe-delimited tokens analogous to ChatML's role-delineation syntax (e.g.,<|system|>,<|assistant|>), but with uppercase content — a deliberate choice to test whether the pipe syntax retains its elevated attention priority when the enclosed text diverges from the lowercase convention.
To test the robustness of the model's attention, "noise" in the form of third-party library source code was added to the prompt. The amount of noise was gradually increased to bring the total context size to 10k, 100k, and 800k tokens.
Evaluation Metrics
Two primary metrics were used to evaluate the efficiency of the models' internal attention mechanisms:
- Adherence Rate: The percentage of responses that genuinely started with the secret code
V8_PASSEDwithout superfluous reasoning or greetings. If the model started with lengthy explanations or a greeting, it was considered a failure. - Confidence: A mathematical indicator of the entropy observed in the probability distribution when selecting the first token of its answer. It is calculated based on logarithmic probabilities (logprobs) — the model's internal certainty about its chosen token. The higher the Confidence, the less the algorithm wavers, and the stronger the instruction signal outweighs the surrounding noise. Studies show that internal generation entropy[4] is far more reliable than "verbalized confidence" (when an LLM writes "I am 90% confident"), which is often a hallucination. Internal metrics serve as an objective indicator of the true memory performance of the neural network.
Model Performance Analysis
During the benchmark, we carefully measured the performance of four different models, which revealed interesting characteristics of their attention mechanisms.

1. Gemini 2.5 Flash: Instability Over Distance
The Gemini 2.5 Flash model exhibited the characteristic patterns of the "Lost in the Middle" problem, with high result instability even between repeated runs of the same test.
- Even at a relatively short context (10,000 tokens), the model showed unstable results across formats: the XML tag group at 10k displayed wide Confidence variance from 35.25% (xml_low_specific) to 76.66% (xml). The xml tag itself achieved only 30% Adherence, while xml_low scored 0%, indicating that tag-level instability manifests even before scaling the context.
- At 800,000 tokens, most standard tags failed: xml (0%), xml_low (0%), xml_namespace_low (0%), custom_2997 (0%), special (0%). The custom format declined to 50% Adherence (93.08% Confidence), confirming a significant degradation compared to shorter contexts.
- The only formats that achieved 100% Adherence at 800k were xml_low_specific (Confidence 99.67%), custom_specific (99.25%), and custom_27EA with Unicode brackets
⟪...⟫(Confidence 57.78%). The first two share the unique suffixff54, which adds artificial entropy and acts as an attention anchor, while the third succeeds despite low Confidence, suggesting that rare typographic symbols can also force attention redirection even without a confidence guarantee.

2. Gemini 2.5 Flash Lite: Optimized Instruction Following
The Gemini 2.5 Flash Lite model demonstrated results exceeding baseline expectations.
- Unlike its larger counterpart, the Adherence Rate was 100% across all 27 tests, regardless of the type of delimiter used (XML, special tokens, custom text) and context length (from 10k to 800k tokens).
- Confidence varied depending on the tag format. Most custom and special tags maintained a stable 98–99%; however, the uppercase xml tag showed noticeably lower confidence: 61% at 10k and 53% at 100k. Meanwhile, its lowercase XML counterpart (xml_low) already showed 95%. This indicates that even for optimized models, tag case and visual specificity matter for internal probabilistic confidence.
- At 800k tokens, confidence ranged from 88.77% (xml) to 99.30% (custom_2997). Despite the spread, the safety margin was sufficient for 100% instruction execution in all cases. This indicates deep instruction tuning optimization of the Lite architecture for strict instruction-following tasks, making it an excellent cost-effective choice for RAG systems (applications where the neural network seeks answers across external knowledge bases and documents).

3. Gemini 3 Flash Preview: An Architectural Breakthrough
The most significant results were obtained during the testing of the Gemini 3 Flash Preview model.
- It showed absolute flawlessness: 100% Adherence across all 27 tested combinations (9 formats × 3 context lengths).
- The key difference from the Lite version lies in the probabilistic Confidence parameter. The lowest recorded value was 99.57% (xml_namespace_low at 800k), and in most tests, Confidence was exactly 100.00%. Even at 800k tokens, the first token probability distribution was near-deterministic during generation.
- This is direct evidence of a major architectural leap in attention modeling mechanisms. While Lite, despite 100% accuracy, still "wavered" with 53–88% confidence for some tags, Gemini 3 maintains consistently high performance in the 99.57–100% range regardless of format. The "Lost in the Middle" effect for third-generation models has been virtually eliminated.
4. DeepSeek V4 Flash: Inverted Attention Curve and Special Token Weakness
The results for the DeepSeek V4 Flash model present a fundamentally different picture of attention distribution compared to all three Gemini models, indicating fundamental architectural differences in the processing of structural markers.
A sharply context-dependent pattern instead of the classical U-shaped degradation. Unlike Gemini, which performs worst at ultra-long distances (800k), DeepSeek showed a total failure at short context — 0% Adherence across all 9 formats at 10k tokens. At 100k, the model unexpectedly "wakes up": 6 out of 9 formats reach 100% Adherence, with xml_low, custom, and custom_specific achieving confidence of 99.90–99.98%. At 800k, the pattern shifts: some XML formats hold (5 out of 9 at 100%), while most custom text formats fail (3 out of 4 at 0%), with custom_2997 as the exception (100%, 61.92% Confidence). This is an inverse pattern: on short context, the model may critically evaluate whether a tag-wrapped directive is a genuine instruction or a test artifact — Confidence values of 46–76% for half the formats indicate a moderately confident decision to ignore it. At 100k+, this discriminative ability degrades, and the model defaults to executing any instruction in a recognized format. The resulting pattern is sharply context-dependent: failure at short distances, near-perfect recovery at medium scale, and format-dependent fragmentation at 800k — the mirror image of the gradual degradation expected under the classical Lost in the Middle effect.
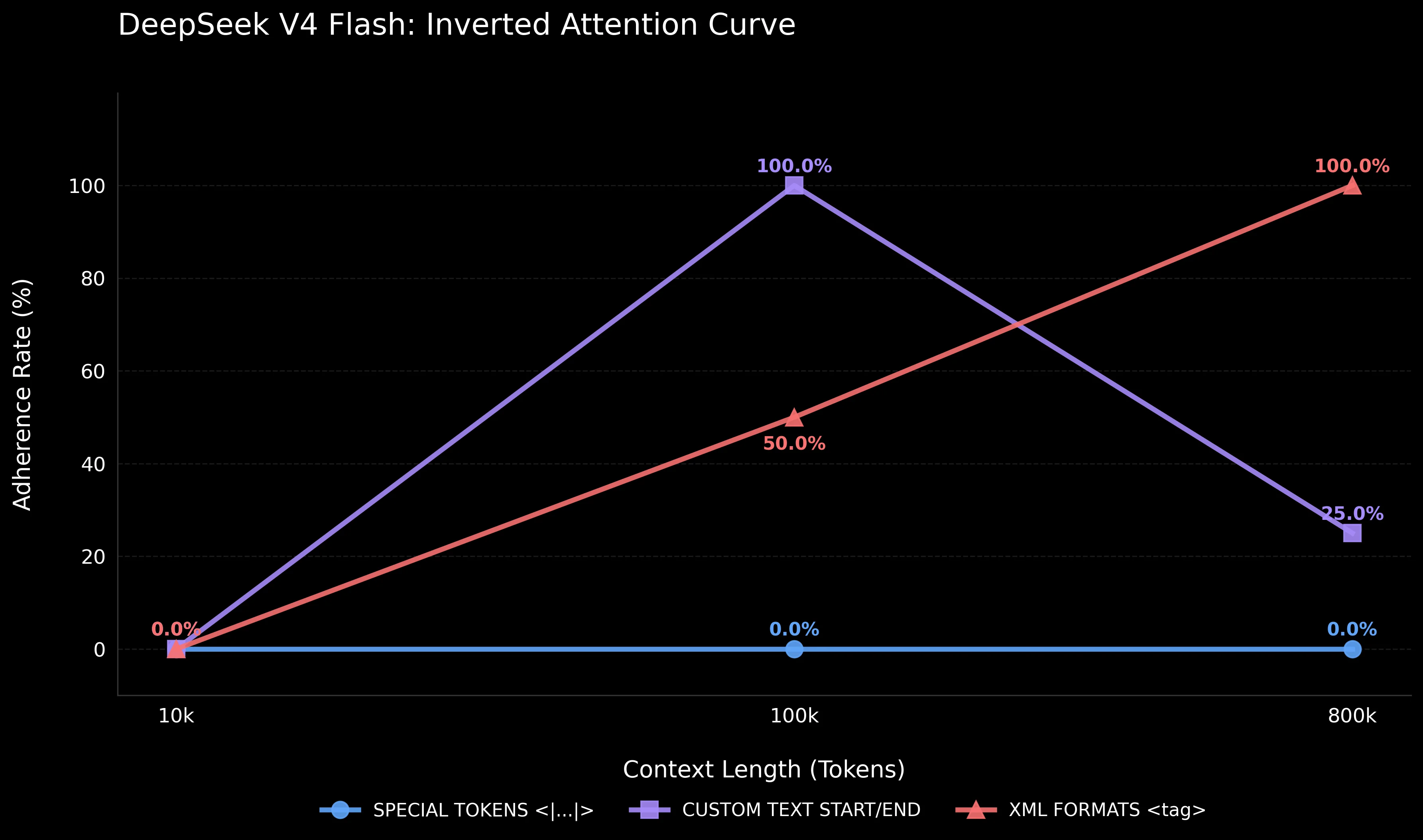
Special tokens <|...|> — a total failure. For Gemini 2.5 Flash Lite, special tokens were among the most reliable formats (98–99% confidence at all lengths). For DeepSeek — a complete failure: 0% Adherence at all three lengths (10k, 100k, 800k). Even at 10k, where confidence reached 76.44%, the model ignored the instruction and began with an expanded code analysis. Notably, DeepSeek V4 extensively uses pipe-delimited tokens in its own protocol — <|User|>, <|Assistant|>, <|action|>, and the DSML tool-call namespace <|DSML|...> — but only for specific known tokens. An unrecognized pipe token like <|INTEGRITY_CHECK|> is treated as noise rather than a signal. This contrasts with Gemini, where pipe syntax inherently triggers elevated attention priority regardless of the specific token name.
XML formats — unexpected resilience at large distances. At 800k tokens, all four XML formats (xml, xml_low, xml_low_specific, xml_namespace_low) showed 100% Adherence — even <INTEGRITY_CHECK> in uppercase, which gave 0% for Gemini 2.5 Flash. However, confidence varied widely: from 38.10% (xml) to 99.75% (xml_low). This contrasts with Gemini, where XML formats were the least reliable — for DeepSeek, they proved to be the only group consistently working at 800k.
Artificial entropy provides no guarantees. The unique suffix _ff54 is not a panacea for DeepSeek: xml_low_specific failed at 10k (0%) and 100k (0%), but worked at 800k (100%, though confidence was only 26.45%). custom_specific failed at 10k and 800k. Entropy, so effective for awakening Gemini's attention, does not yield a predictable effect for DeepSeek.
Practical Conclusion: DeepSeek V4 Flash requires a fundamentally different approach to prompt engineering. Short prompts up to 10k tokens are a risk zone: the model tends to dismiss tagged instructions as test artifacts rather than executing them.
Note: Among additionally tested variants (not included in the benchmark tables below), rare Unicode brackets with explicit START/END markers (
⦗START_INTEGRITY_CHECK⦘…⦗END_INTEGRITY_CHECK⦘) were the only format achieving 100% Adherence at all three lengths (99.21% → 70.40% → 23.30% Confidence), suggesting that maximal visual entropy combined with asymmetric open/close semantics can override even the model's short-context critical filter.
At medium distances (100k), xml_low and custom/custom_specific are optimal. At 800k, the most reliable strategy is lowercase XML tags (xml_low, 99.75% confidence), while special tokens and most custom text formats fail — with the notable exception of custom_2997 (100%, 61.92% Confidence).
Tag Microdynamics: What Does the Confidence Analysis Show?
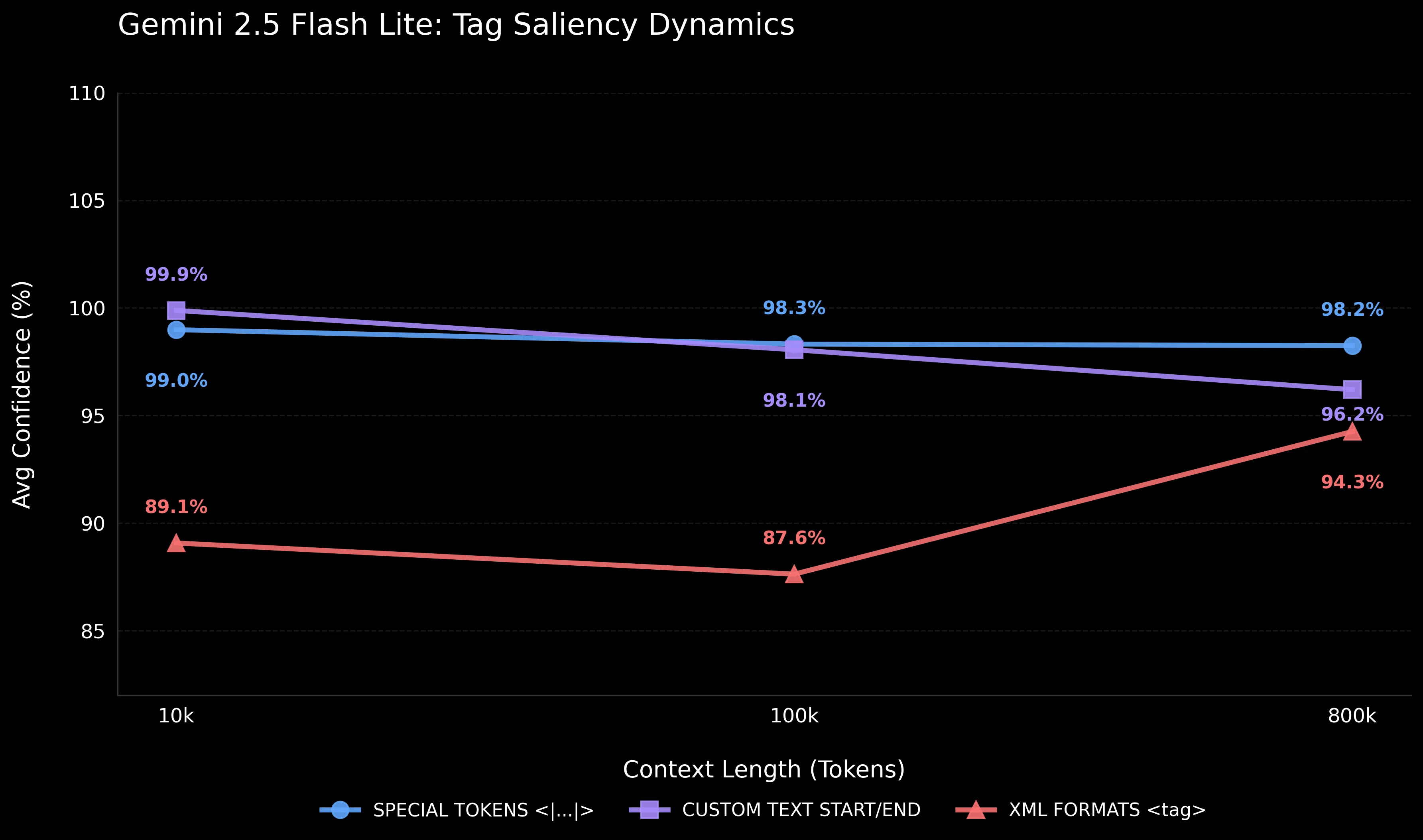
Despite the high Adherence Rates in optimized models like Gemini 2.5 Flash Lite, investigating the microdynamics of their Confidence parameters reveals critical patterns in how attention algorithms perceive different structures over long distances (from 10k to 800k tokens).
Even when a model succeeds at the task 100% of the time, its "probabilistic fluctuations" when choosing the first token of the answer depend on the type of delimiter used (as shown in the Tag Saliency Dynamics chart):
-
Special Tokens (
<|...|>): For Gemini 2.5 Flash Lite, special tokens show a flat confidence line (stable 98–99% at any distance). However, this is not a universal property of LLMs: for DeepSeek V4 Flash and Gemini 2.5 Flash, special tokens fail completely (0% Adherence at 100k and 800k). We hypothesize that the effect is architecture-dependent. It is highly likely that models utilizing pipe-delimited tokens in their training protocol maintain high priority for them, whereas others may treat unrecognized<|...|>constructs as noise. -
Custom Text: Demonstrates a gradual drop in confidence as context grows for most variants. Starting from the highest values at 10k tokens (nearly 100%), markers like
START_INTEGRITY_CHECK...END_INTEGRITY_CHECKgradually lose their saliency. By 800k tokens, the average confidence across custom formats declines to ~96%, though custom_2997 (⦗...⦘) remains an outlier at 99.30%. The reason is that plain text words often blend in with the noise (variables in code, unstructured text), making it increasingly difficult for the model to latch onto them in a gargantuan context. -
XML (XML tags): Shows the lowest average confidence (87–94%) and the highest instability. This average range masks intense internal fluctuations: a standard uppercase tag drops confidence down to 53%, and improvement is observed exclusively when using unique suffixes. Although the instruction itself isn't lost (Adherence 100%), the abundance of XML code in training datasets makes standard brackets too "mundane", causing a meta-instruction without additional anchors to stand out less effectively.
Conclusions and Recommendations for Prompt Engineering
In our study, source code served as the 'noise' factor — the native environment for autonomous programming agents. This means our findings translate directly to making such agents more robust at scale. But the implications extend beyond code: the mechanics of self-attention are indifferent to the nature of the tokens. Loss of focus is driven by overloading the "attention budget"[5] and the emergence of "attention basins"[3], which cause the model to ignore the middle of the context — regardless of whether that context is code or natural text.
Furthermore, a large code array acts as an extreme stress test due to dual interference:
- Structural: The abundance of syntax and service tokens (
def,class) acts as "false beacons", drawing attention away and drowning out plain text tags. - Semantic: The technical nature of the hidden instruction blends with the background code, provoking "context bleeding" and hindering the model from separating the task itself from the noise.
Our benchmark confirms: structuring system prompts and choosing appropriate tagging strategies for LLM tasks must be a deliberate design process, not an afterthought. This is particularly crucial in two scenarios:
- Multi-turn agentic systems: The "Lost in Conversation"[7] problem, where agents forget critical initial instructions due to a long interaction history.
- RAG pipelines (knowledge base search): When multiple retrieved documents are loaded into the prompt, and the useful system instruction is diluted against the backdrop of "noisy" data. This leads to the "context bleeding" effect, where the model confuses instructions with document contents.
Key Recommendations:
-
Avoid "clean" tags without unique identifiers on models prone to the "Lost in the Middle" effect. The data showed: at 800k tokens for Gemini 2.5 Flash, the vast majority of standard tags without unique suffixes failed —
<INTEGRITY_CHECK>(0%),<integrity_check>(0%),<sys:integrity_check>(0%),⦗INTEGRITY_CHECK⦘(0%),<|INTEGRITY_CHECK|>(0%).START_INTEGRITY_CHECKdeclined to 50%, confirming degradation. The only exception was Unicode brackets⟪INTEGRITY_CHECK⟫(100% Adherence, but with low 57.78% Confidence), making them an unreliable option. -
Use artificial entropy as an attention anchor — for architectures susceptible to the Lost in the Middle effect. Out of all the tags tested at 800k for Gemini 2.5 Flash, the variants with the
ff54suffix worked stably and with high confidence:<integrity_check_ff54>(100% Adherence, 99.67% Confidence) andSTART_INTEGRITY_CHECK_ff54(100%, 99.25%). A marker with high entropy (uniqueness) forcefully directs the model's self-attention into the "blind spot" of the context. However, for DeepSeek, this strategy is unstable and model-specific. -
Consider the impact of case on the confidence of optimized models. Although for Gemini 2.5 Flash, XML tag case does not exert a statistically significant influence in large contexts, for Gemini 2.5 Flash Lite, the difference was significant: the
<INTEGRITY_CHECK>tag (uppercase) showed confidence of 53–89%, while<integrity_check>(lowercase) showed 95–98%. For DeepSeek V4 Flash at 800k, the picture is even more dramatic:<INTEGRITY_CHECK>— 38.10% confidence,<integrity_check>— 99.75%. Lowercase XML tags consistently outperform uppercase on all tested models. -
For Gemini 3, tag format is not critical. All 27 tests showed 100% Adherence with a confidence of 99.57–100%. However, using a clean, well-structured prompt (creating strict XML "grammar")[5] remains best practice for minimizing hallucination risks in complex agentic chains.
-
Account for architectural characteristics when choosing a tagging strategy. What works for one model may be useless or harmful for another. For the Gemini family, special tokens
<|...|>are the optimal choice. For DeepSeek V4 Flash, special tokens are a guaranteed failure (0% at all distances), and the only reliable strategy at 800k is lowercase XML tags. For short prompts (up to 10k), DeepSeek requires special caution: at these distances, the model tends to dismiss tagged instructions as test artifacts rather than executing them, making it a risky choice for scenarios with compact but critical context.
Model-Specific Recommendations
The choice of tagging strategy must be governed by the target model's architecture:
- Gemini 2.5 Flash (Lost-in-the-Middle-prone): Requires artificial entropy. Use unique suffixes (
_ff54or similar) — the only reliable way to maintain 100% Adherence at 800k+ contexts. - Gemini 2.5 Flash Lite (optimized): All formats work at 100% Adherence, but optimal confidence is achieved with lowercase XML tags (xml_low, xml_namespace_low) or special tokens (
<|...|>). Uppercase XML tags suppress confidence significantly. - Gemini 3 Flash Preview (attention-stable): Tag format is not critical. Any consistent delimiter achieves near-deterministic confidence (99.57–100%).
- DeepSeek V4 Flash (inverted curve): Lowercase XML tags are the only consistently reliable strategy at 800k contexts. Special tokens cause guaranteed failure (0% at all lengths). Short prompts (<10k) are a risk zone — the model tends to dismiss tagged instructions as test artifacts. For full-length coverage (10k–800k), Unicode brackets with explicit START/END markers (
⦗START…⦘/⦗END…⦘) are the only format that achieved 100% Adherence at all three context lengths, albeit with degrading confidence (99% → 70% → 23%).
In an era where LLM context windows are measured in millions of tokens, clean, precise markup of structural blocks remains the foundation of AI predictability.
We considered these findings when developing SpecTree. Using tree-like XML markup and adding unique markers to key specification sections helps us improve the stability of AI agents working with massive requirements documents. This approach allows us to reduce information noise around critical instructions and make the document structure more "transparent" to the attention mechanisms of modern LLMs.
Sources:
[1] Lost in the Middle: How Language Models Use Long Contexts (Liu et al., TACL 2024). A study of the U-shaped attention curve and extraction degradation from the middle of the context.
[2] BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack (Kuratov et al., 2024). Stress-testing methodology for models over ultra-long distances.
[3] Attention Basin: Why Contextual Position Matters in Large Language Models (Yi et al., 2025). Analysis of the macro-level phenomenon of "attention basins" that arise when a model processes structural boundaries of text documents.
[4] Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation (Kuhn et al., 2023). Demonstrates that entropy-based uncertainty measures outperform verbalized confidence scores in detecting hallucinations and incorrect model outputs.
[5] Effective context engineering for AI agents (Anthropic, 2025). Justification for the overloading of Transformer mathematical connections, the concept of an exhaustible "attention budget", and principles of using XML grammar.
[6] RULER: What's the Real Context Size of Your Long-Context Language Models? (Hsieh et al., 2024). A benchmark of effective context length to detect performance degradation.
[7] LLMs Get Lost In Multi-Turn Conversation (Laban et al., 2025). A study of attention degradation during multi-turn interaction in agentic systems.
[8] DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence (DeepSeek-AI, 2026). Technical report describing the Hybrid Attention Architecture (CSA + HCA) with Compressed Sparse Attention and its 1M-token context optimization.
Appendix: Benchmark Summary Data
This section presents detailed test results for all tested models. Table cells display two key parameters separated by a slash:
- Adh (Adherence Rate) — the percentage of responses where the model executed the instruction without extraneous reasoning (target: 100%).
- Conf (Confidence) — the probabilistic confidence metric of the model when choosing the first response token (based on logprobs).
Table 1. Gemini 2.5 Flash Results
| Tag Format | 10k (Adh/Conf) | 100k (Adh/Conf) | 800k (Adh/Conf) |
|---|---|---|---|
| xml <INTEGRITY_CHECK>...</INTEGRITY_CHECK> | 30 / 76.66% | 50 / 81.03% | 0 / 0.00% |
| xml_low <integrity_check>...</integrity_check> | 0 / 56.78% | 50 / 81.14% | 0 / 56.11% |
| xml_low_specific <integrity_check_ff54>...</integrity_check_ff54> | 50 / 35.25% | 100 / 98.53% | 100 / 99.67% |
| xml_namespace_low <sys:integrity_check>...</sys:integrity_check> | 50 / 59.89% | 100 / 69.73% | 0 / 43.19% |
| custom START_INTEGRITY_CHECK...END_INTEGRITY_CHECK | 83 / 77.34% | 100 / 99.83% | 50 / 93.08% |
| custom_specific START_INTEGRITY_CHECK_ff54...END_INTEGRITY_CHECK_ff54 | 20 / 66.25% | 50 / 92.00% | 100 / 99.25% |
| custom_27EA ⟪INTEGRITY_CHECK⟫...⟪INTEGRITY_CHECK⟫ | 50 / 82.62% | 50 / 74.95% | 100 / 57.78% |
| custom_2997 ⦗INTEGRITY_CHECK⦘...⦗INTEGRITY_CHECK⦘ | 75 / 79.33% | 50 / 75.52% | 0 / 51.50% |
| special <|INTEGRITY_CHECK|>...<|INTEGRITY_CHECK|> | 50 / 98.23% | 0 / 42.05% | 0 / 0.00% |
Table 2. Gemini 2.5 Flash Lite Results
| Tag Format | 10k (Adh/Conf) | 100k (Adh/Conf) | 800k (Adh/Conf) |
|---|---|---|---|
| xml <INTEGRITY_CHECK>...</INTEGRITY_CHECK> | 100 / 61.29% | 100 / 53.18% | 100 / 88.77% |
| xml_low <integrity_check>...</integrity_check> | 100 / 95.38% | 100 / 98.73% | 100 / 95.45% |
| xml_low_specific <integrity_check_ff54>...</integrity_check_ff54> | 100 / 99.76% | 100 / 99.28% | 100 / 93.96% |
| xml_namespace_low <sys:integrity_check>...</sys:integrity_check> | 100 / 99.88% | 100 / 99.34% | 100 / 98.86% |
| custom START_INTEGRITY_CHECK...END_INTEGRITY_CHECK | 100 / 99.90% | 100 / 99.64% | 100 / 95.08% |
| custom_specific START_INTEGRITY_CHECK_ff54...END_INTEGRITY_CHECK_ff54 | 100 / 99.89% | 100 / 99.61% | 100 / 97.12% |
| custom_27EA ⟪INTEGRITY_CHECK⟫...⟪INTEGRITY_CHECK⟫ | 100 / 99.83% | 100 / 93.09% | 100 / 93.31% |
| custom_2997 ⦗INTEGRITY_CHECK⦘...⦗INTEGRITY_CHECK⦘ | 100 / 99.92% | 100 / 99.89% | 100 / 99.30% |
| special <|INTEGRITY_CHECK|>...<|INTEGRITY_CHECK|> | 100 / 98.99% | 100 / 98.32% | 100 / 98.25% |
Table 3. Gemini 3 Flash Preview Results
| Tag Format | 10k (Adh/Conf) | 100k (Adh/Conf) | 800k (Adh/Conf) |
|---|---|---|---|
| xml <INTEGRITY_CHECK>...</INTEGRITY_CHECK> | 100 / 100.00% | 100 / 99.99% | 100 / 100.00% |
| xml_low <integrity_check>...</integrity_check> | 100 / 100.00% | 100 / 99.99% | 100 / 99.95% |
| xml_low_specific <integrity_check_ff54>...</integrity_check_ff54> | 100 / 100.00% | 100 / 100.00% | 100 / 100.00% |
| xml_namespace_low <sys:integrity_check>...</sys:integrity_check> | 100 / 100.00% | 100 / 100.00% | 100 / 99.57% |
| custom START_INTEGRITY_CHECK...END_INTEGRITY_CHECK | 100 / 100.00% | 100 / 100.00% | 100 / 100.00% |
| custom_specific START_INTEGRITY_CHECK_ff54...END_INTEGRITY_CHECK_ff54 | 100 / 100.00% | 100 / 100.00% | 100 / 100.00% |
| custom_27EA ⟪INTEGRITY_CHECK⟫...⟪INTEGRITY_CHECK⟫ | 100 / 99.99% | 100 / 99.99% | 100 / 100.00% |
| custom_2997 ⦗INTEGRITY_CHECK⦘...⦗INTEGRITY_CHECK⦘ | 100 / 99.99% | 100 / 100.00% | 100 / 99.95% |
| special <|INTEGRITY_CHECK|>...<|INTEGRITY_CHECK|> | 100 / 100.00% | 100 / 100.00% | 100 / 100.00% |
Table 4. DeepSeek V4 Flash Results
| Tag Format | 10k (Adh/Conf) | 100k (Adh/Conf) | 800k (Adh/Conf) |
|---|---|---|---|
| xml <INTEGRITY_CHECK>...</INTEGRITY_CHECK> | 0 / 11.51% | 0 / 58.08% | 100 / 38.10% |
| xml_low <integrity_check>...</integrity_check> | 0 / 0.26% | 100 / 99.90% | 100 / 99.75% |
| xml_low_specific <integrity_check_ff54>...</integrity_check_ff54> | 0 / 47.73% | 0 / 1.51% | 100 / 26.45% |
| xml_namespace_low <sys:integrity_check>...</sys:integrity_check> | 0 / 12.70% | 100 / 62.35% | 100 / 40.61% |
| custom START_INTEGRITY_CHECK...END_INTEGRITY_CHECK | 0 / 45.53% | 100 / 99.89% | 0 / 17.19% |
| custom_specific START_INTEGRITY_CHECK_ff54...END_INTEGRITY_CHECK_ff54 | 0 / 10.12% | 100 / 99.98% | 0 / 36.84% |
| custom_27EA ⟪INTEGRITY_CHECK⟫...⟪INTEGRITY_CHECK⟫ | 0 / 46.17% | 100 / 60.42% | 0 / 4.11% |
| custom_2997 ⦗INTEGRITY_CHECK⦘...⦗INTEGRITY_CHECK⦘ | 0 / 4.93% | 100 / 98.69% | 100 / 61.92% |
| special <|INTEGRITY_CHECK|>...<|INTEGRITY_CHECK|> | 0 / 76.44% | 0 / 48.21% | 0 / 69.28% |